SQL Performance Tuning: Finding Duplicate & Redundant Indexes
In this blog, we'll cover redundant and duplicate indexes, which are quite common in applications and affect database performance.
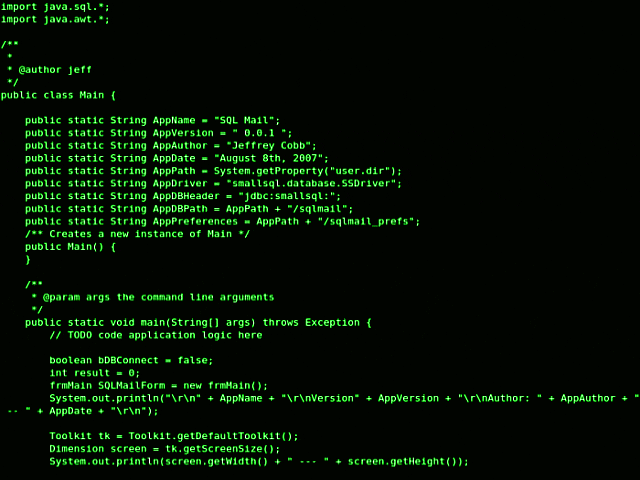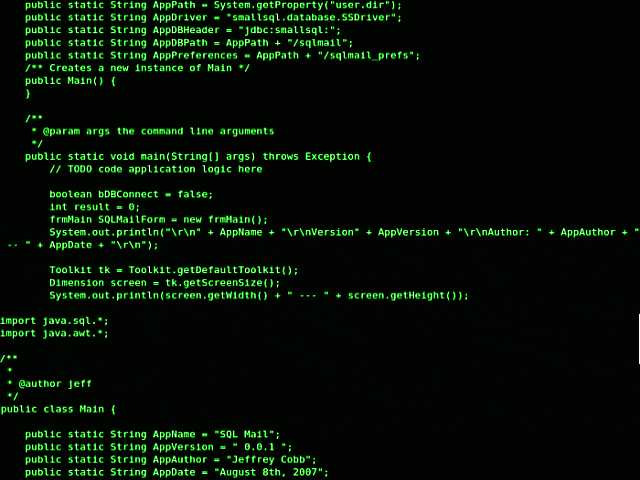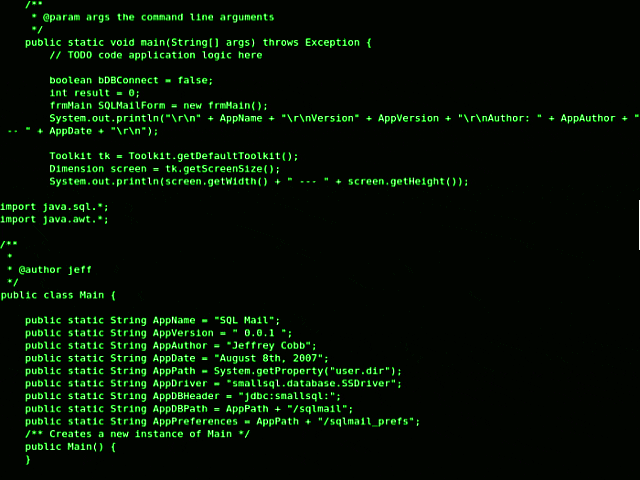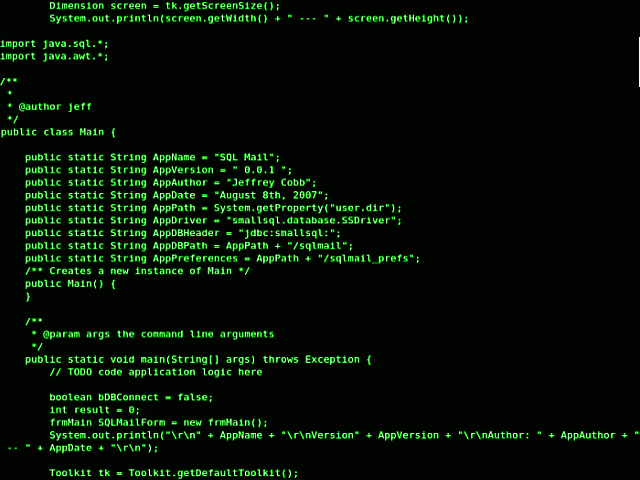
An index is duplicated when there is more than one defined on a single column. Such indexes may have varying names or keywords used to define them at times. A common instance may be something like PRIMARY KEY (iden), UNIQUE KEY iden (iden), KEY iden2 (iden).
How Duplicate Indexes are Created - and Found
These are often found during SQL performance tuning, and many users do this because they intend to use primary key as object identifier, after which they create the unique key to, well, keep the data unique. This is followed by a third KEY that can be utilized in the queries.
It's a wrong practice in general because it slows down MySQL. Besides, creating a PRIMARY KEY is simply enough as it will enforce unique values and be used in the queries.
Another possible reason for creating several keys for the same column is that the user created the new ones without realizing there was a key already created for that column. This is something to be careful about in Oracle database and SQL , because MySQL allows users to create multiple indexes, which is rather lenient for users but can lead to performance issues in the future.
Moreover, these extra keys also require space on the disk and the memory as they will be stored inside the storage engine, and will require updating during data manipulation commands (update, insert, delete) in Oracle database and SQL. In short, duplicate indexes are bad news, so users need to remove them as soon as they find any of them.
Redundant Indexes: Why You Need to Get Rid of Them Too
Redundant indexes are often called BTree indexes by some experts, and the reason behind this can be understood by the following example:
KEY (X), KEY (X, Y), KEY (X (15))
Here, the first and last indexes are redundant. This is because they can be considered the prefix of the middle index, ie, KEY (X, Y), which is why such indexes are given the nickname BTree indexes.
Queries that use these redundant indexes can also use longer indexes, which will result in poor performance, and the subsequent need for SQL performance tuning . Redundant indexes, therefore, also need to be eliminated at the first opportunity.
However, there are situations where this type of indexes actually proves useful, such as in the case of a significantly longer index. For instance, if X is integer and Y is varchar (295), it may hold several lengthy values using KEY (X) in a quicker manner than it would using KEY (X, Y).
Some cases, therefore, may require additional consideration before deciding to remove the redundant indexes. A typical instance where you may leave out shorter indexes and include longer ones may be in cases where you want a query to execute as a query covered by an index (to fetch every column from the index, say). Such indexes are usually too long for efficient application by other queries.